优化Linux内核参数
提高服务器性能有很多方法,比如划分图片服务器,主从数据库服务器等,本文要讲的是在硬件资源有限的情况下,修改 Linux 的内核相关 TCP 参数,来最大的提高服务器并发性能。当然,最简单的提高负载问题,还是升级服务器硬件了。
- 网络相关的内核参数,net.* 中常用的
- 非网络相关的,如 fs. kernel. 等等
修改内核参数的方法很简单,root 权限下更改 /etc/sysctl.conf 文件
net相关参数
对于 Linux 服务器来说,net.* 下面的内核参数是比较常用的,尤其提供 TCP 的服务来说。先上一个 TCP 状态转换图帮助理解:
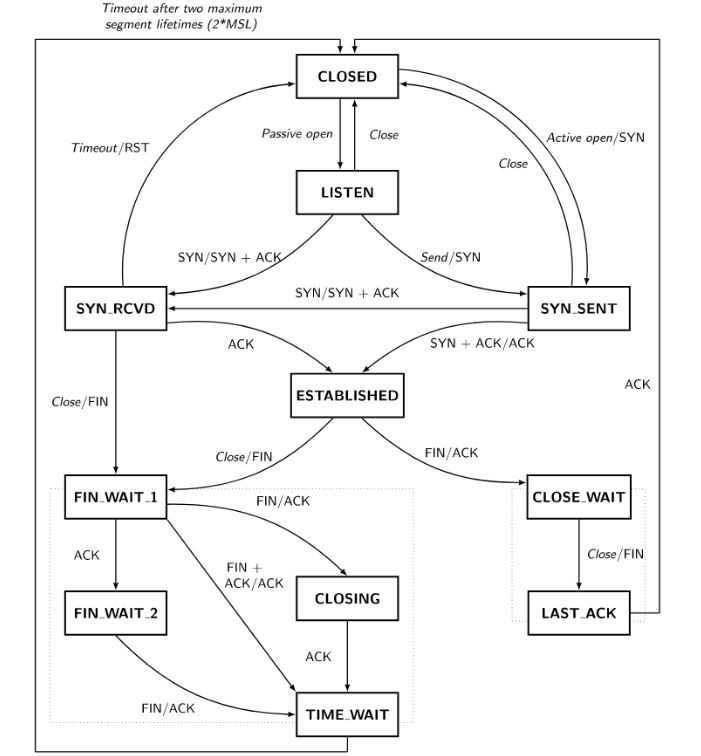
net.ipv4.tcp_tw_reuse
Linux 下,TCP 连接断开后,会以 TIME_WAIT 状态保留一定的时间,然后才会释放端口。当并发请求过多的时候,就会产生大量的 TIME_WAIT 状态的连接,无法及时断开的话,会占用大量的端口资源和服务器资源。
tcp_tw_reuse 默认为0关闭,设置为1打开,作用是让处于 TIME_WAIT 的状态的 TCP 连接的资源可以不用等 2MSL,1s 之后直接被复用,重新发起 SYN 包,经过 SYN - FIN_ACK- RST - SYN - SYN_ACK 重新进入 ESTABLISHED 状态。
通俗一点解释,比如下面 ss 命令,有33个 TIME_WAIT 状态的 TCP 连接,可以想象一下,就在2分钟内(Linux默认的2MSL时间),可能有浏览器关闭了页面,或是短连接获取完数据自己关闭,用 ACK 消息回复对端 FIN 之后,仍然不敢直接复用而是进入 TIME_WAIT 状态,因为:
虽然 TCP 保证了顺序,但复杂的网络状况可能导致多次包重传,对端在 FIN 之前的 数据包 可能都还没有过来,直接复用原来的连接可能会导致新的连接收到上个连接中重传的“幽灵数据包”
担心收到 FIN 之后回复的 ACK 对端收不到,于是本端苦苦等待网络包最长存在时间的两倍来兜底
可以使用 ss 命令去查看 TIME_WAIT 连接状态:
ss -s
1 | Total: 141 |
因此,对于服务器来说,TCP 连接在被动关闭的情况下,并不存在 TIME_WAIT 状态,很多时候是不需要修改这个参数的,如果出现 TIME_WAIT 过多,也不要盲目配置此参数,想一想原因,netstat 找一找是哪些连接在 TIME_WAIT,可能的典型场景有这些:
- 用于压测的客户端机器:作为客户端不停地发起大量 TCP 连接
- 短连接调用的微服务场景:A服务调B服务,B服务调C服务,虽然大家都是服务器,但是互相调用时,调用方也是客户端(用http2,gRPC等只产生少量长连接的RPC协议除外)
- 转发大量请求到外部服务:比如 Nginx,HAProxy,Traefik 等反向代理,或是服务端有对外调用第三方开放平台服务的场景,因为大部分平台提供的都是 HTTP API,比较容易产生 TIME_WAIT 的积压
另外,服务端在内存充裕的情况下,也可以增大 net.ipv4.tcp_max_tw_buckets 来提高最大允许的 TIME_WAIT 状态的 TCP 连接数量。
net.ipv4.tcp_fin_timeout
很多人理解这个参数为控制 TCP TIME_WAIT 状态的超时时间,这种说法是错误的。因为,这个参数只能改4次挥手第2步完成(收到FIN_ACK)进入 FIN_WAIT_2 后,最长等待的超时时间。
也就是这个参数决定了它保持在 FIN-WAIT-2 状态的时间。默认60s,在网络状况很好的情况下可以减少到10-30s。
net.ipv4.tcp_syncookies
此参数默认已经是打开了,不确定是那个版本开始的,打开可以防止大部分 SYN 洪水攻击。
- SYN Flood 原理是伪造大量三次握手的第一次 SYN 包,让对端产生大量半连接状态的 TCP 连接直至资源耗尽
- SYN Cookies 防止 SYN Flood 的原理是通过记录第一个 SYN 包部分信息 Hash,然后在握手最后一步 ACK 来校验,校验成功后才真正分配连接资源
- SYN Cookies 消耗少量计算资源,避免了伪造 SYN 包导致大量半连接状态的 TCP 连接
SYN Cookies 是一种用 HMAC 手段来达到延迟初始化和资源分配的目的,搭配下面两个参数可以对半连接状态做更多的优化:
- net.ipv4.tcp_synack_retries: 默认5,如果 SYN 没有 SYN_ACK,默认重试5次,可以适当降低
- net.ipv4.tcp_max_syn_backlog:在达到 ESTABLISHED 之前,半连接状态的 TCP 连接最大数量,默认值不同发行版不同,找了几种版本看默认值都在128~512之间,视网络状况和具体应用可以适当调整
注:这里的 syn_backlog 和 linux 中 listen 系统调用中的 backlog 参数区别在于,listen 参数中的 backlog 是监听的 port 最大允许的未 ACCEPT 的 ESTABLISHED 状态连接数和 SYNC_RCVD 状态连接数之和,而 syn_backlog 是系统层面最大允许的半连接数(SYNC_RCVD状态的连接)之和:
1 |
|
linux 遵循的 POSIX 标准,并不完全是 TCP 标准,backlog 不会影响 accept() 之后的连接数,而是像一个待处理缓冲区,具体分析可以参考这些文章:
- http://veithen.io/2014/01/01/how-tcp-backlog-works-in-linux.html
- https://segmentfault.com/a/1190000019252960
net.core.tcp_somaxconn
这个参数也有不少人误解,有些 Nginx 的 Tuning 方案认为这是最大连接数,建议把这个值从默认值128改大一些,甚至改到655360,这种理解是不正确的。
首先来理解一下这个参数的含义,somaxconn 不是指每个 listen 端口的的最大连接数,而是指 max backlogged connections, backlog 的含义可以看上面的文章,大致可以理解为在应用层 accept 之前的缓冲区大小。
因此,如果服务端处理能力有盈余,及时 accept 了,就没必要调整这个参数了,尤其是现在主流框架都是单独的 I/O 线程循环 accept 和 read,真正的处理都放到 Worker 线程,128足矣,边缘入口服务如 Nginx 机器改成512(Nginx默认listen backlog参数为511)也足矣。
net.ipv4.ip_local_port_range
默认值 32768 60999,含义是端口号从32768到60999都可以作为建立 TCP 连接的端口,默认接近 3w 个连接基本足够了,使用场景与 tcp_tw_reuse 类似。优先去找过多连接导致端口号耗尽的根本原因,切忌盲目修改内核参数,即使看起来没有太大副作用。
net.ipv4.tcp_keepalive_time
默认长连接 TCP KeepAlive 包是两小时发送一次(7200),Nginx 等反向代理服务,可以降低这个参数的值。本身提供长连接的服务比如 WebSocket,大多都会有应用层/协议层的保活机制,个人感觉其实没有必要改这个参数。
net.ipv4.ip_forward
ip forward 即对 IP 包做路由,大多数情况下是不需要的,如果被打开了,可以设置为0关闭掉。多网卡做软路由的场景,则需要打开这个功能。需要注意:在 Kubernetes 集群中,需要打开 ip forward 功能,否则某些 CNI 实现会出问题。
net.ipv4.tcp_congestion_control
TCP 拥塞控制算法,低内核版本的 Linux 就不用改这个了,在4.9及以上版本的内核,Linux 提供了新的 TCP 拥塞控制算法 BBR。下面是 Linux 上开启 BBR 的方式:
1 | net.core.default_qdisc = fq |
net.ipv4.tcp_slow_start_after_idle
关闭慢启动重启(Slow-Start Restart), SSR 对于会出现突发空闲的长周期 TLS 连接有很大的负面影响,建议关闭:
net.ipv4.tcp_slow_start_after_idle = 0
net.ipv4.tcp_mtu_probing
启用 MTU 探测,在链路上存在 ICMP 黑洞时候启用,设置0为禁用,1默认关闭,当检测到 ICMP 黑洞时启用,2始终启用,使用 tcp_base_mss 的初始 MSS。建议设置为1:
net.ipv4.tcp_mtu_probing = 1
Socket Read/Write Memory
有4个参数控制着 Socket 发送(Write)、接收(Read)数据的缓冲区大小。这个缓冲区是不分 TCP UDP 的,TCP 在 net.ipv4 下面也有单独设置缓冲区大小的参数。下面这样可以把缓冲区增大到3MB~16MB,可以视网络状况、应用场景、机器性能来增大缓冲区。
1 | net.ipv4.tcp_mem = 786432 2097152 3145728 |
fs相关参数
fs.file-max 与 ulimit
指的是 Linux 系统最大能打开的 File Descriptor 数量,用 Windows 的话说就是“最大句柄数”。
推荐配置: fs.file-max = 655360
这个参数非常常用,因为 Linux 下一切皆文件,你以为你只是打开了一个 TCP 连接,虽然不存在读写磁盘文件,但也是要占用文件描述符的!默认的 open files 参数是 1024,这个数值相对于应用 nginx 这类 web 服务是不够的,所以先要修改 open files 参数:
1、 vi /etc/security/limits.conf
添加下面内容:
1 | * soft nproc 655360 |
2、 echo "session required pam_limits.so" >> /etc/pam.d/common-session
3、 echo "session required pam_limits.so" >> /etc/pam.d/common-session-noninteractive
4、 echo "DefaultLimitNOFILE=655360" >> /etc/systemd/system.conf
重启服务器后,可以使用命令 ulimit -n 或者 ulimit -a 查看 open files 参数。
当然 nginx 上也相应需要修改 worker_connections 参数,可以避免 nginx 出现 worker_connections are not enough 报错。
vi /etc/nginx/nginx.conf
1 | worker_rlimit_nofile 655360; |
vm相关参数
vm.swappiness
Linux 的进程使用的内存分为2种:
1、file-backed pages(有文件背景的页面,比如代码段、比如 read/write 方法读写的文件、比如 mmap 读写的文件,它们有对应的硬盘文件,因此如果要交换,可以直接和硬盘对应的文件进行交换;比如读取一个文件,没有关闭,也没有修改,交换时,就可以将这个文件直接放回硬盘,代码处理其实就是删除这部分内容,只保留一个索引,让系统知道这个文件还处于打开状态,只是它的内容不在内存,在硬盘上),此部分页面叫做 page cache;
2、anonymous pages(匿名页,如 stack,heap,CoW 后的数据段等;他们没有对应的硬盘文件,因此如果要交换,只能交换到 swap 分区),此部分页面,如果系统内存不充分,可以被swap 到 swapfile 或者硬盘的 swap 分区。
第(1)种内存是 Linux 系统更 prefer 的 reclaim 区域,它的 IO cost 相对较低;第(2)种 swap 的 IO cost 相对较高。
swappiness 是 Linux 的一个内核参数,控制系统在进行内存 swap 时,使用 swap 分区或 filesystem page cache 的权重。它跟使用了多少百分比的系统内存后才开发 swap 没有关系,这是网络上很多文章的一个错误。
swappiness 参数值可设置范围在0到200之间,中间值是100。
Linux 在进行内存回收(memory reclaim)的时候,实际上可以从1类和2类这两种页面里面进行回收,而 swappiness 值就决定了回收这2类页面的优先级。swappiness 越大,越倾向于回收匿名页;swappiness 越小,越倾向于回收 file-backed 的页面。当然,它们的回收方法都是一样的LRU算法。
那么了解了以上,大家应该也知道怎么设置这个 swappiness 参数了吧,个人建议是不做配置,对这个值进行调整可能在不同工作负载环境中会有不同的效果。一定要注意的是,这个值不要为0。
vm.vfs_cache_pressure
该项表示内核回收用于 directory 和 inode cache 内存的倾向:
缺省值100表示内核将根据 pagecache 和 swapcache,把 directory 和 inode cache 保持在一个合理的百分比
降低该值低于100,将导致内核倾向于保留 directory 和 inode cache
增加该值超过100,将导致内核倾向于回收 directory 和 inode cache
这个参数不建议更改,小内存服务器可设置参数为50
vm.vfs_cache_pressure = 50
总结
此处应该有表格:
| 参数 | 查看默认参数 | 配置说明 |
|---|---|---|
| net.ipv4.tcp_tw_reuse = 1 | cat /proc/sys/net/ipv4/tcp_tw_reuse | 因为很难达到TIME_WAIT连接瓶颈,加上TIME_WAIT过多的原因并不在此,所以不用配置 |
| net.ipv4.tcp_fin_timeout = 15 | cat /proc/sys/net/ipv4/tcp_fin_timeout | 被误以为控制TIME_WAIT状态的超时时间,所以随便配置 |
| net.ipv4.tcp_syncookies = 1 | cat /proc/sys/net/ipv4/tcp_syncookies | 这项默认已经打开了 |
| net.core.tcp_somaxconn = 512 | cat /proc/sys/net/core/somaxconn | 被人误解的参数,这并不是最大连接数,所以不用配置 |
| net.ipv4.ip_local_port_range = 1024 65000 | cat /proc/sys/net/ipv4/ip_local_port_range | 端口范围,默认够用,所以随便配置 |
| net.ipv4.tcp_keepalive_time = 7200 | cat /proc/sys/net/ipv4/tcp_keepalive_time | 默认参数即是7200,所以不用配置 |
| net.ipv4.ip_forward = 1 | cat /proc/sys/net/ipv4/ip_forward | 数据包转发,视情况开启,Kubernetes 集群中需要打开 |
| net.ipv4.tcp_slow_start_after_idle = 0 | cat /proc/sys/net/ipv4/tcp_slow_start_after_idle | SSR 对于会出现突发空闲的长周期 TLS 连接有很大影响,所以关闭 |
| net.ipv4.tcp_mtu_probing = 1 | cat /proc/sys/net/ipv4/tcp_mtu_probing | 设置为1,当检测到 ICMP 黑洞时启用 |
| net.ipv4.tcp_congestion_control = bbr | cat /proc/sys/net/ipv4/tcp_congestion_control | bbr不用说了,打开 |
| net.core.default_qdisc = fq | cat /proc/sys/net/core/default_qdisc | bbr同上 |
| net.ipv4.tcp_mem = 786432 2097152 3145728 | cat /proc/sys/net/ipv4/tcp_mem | 增大缓冲区,一般不用开启 |
| net.ipv4.tcp_rmem = 4096 4096 16777216 | cat /proc/sys/net/ipv4/tcp_rmem | 同上 |
| net.ipv4.tcp_wmem = 4096 4096 16777216 | cat /proc/sys/net/ipv4/tcp_wmem | 同上 |
| fs.file-max = 655360 | cat /proc/sys/fs/file-max | 增加打开的 File Descriptor 数量,建议开启 |
| vm.swappiness = 60 | cat /proc/sys/vm/swappiness | 默认60,建议不要随便改 |
| vm.vfs_cache_pressure = 50 | cat /proc/sys/vm/vfs_cache_pressure | 实际体验不明显,所以随便,数值填写100以上或以下,比如50或者1000 |
重点也就是配置 fs.file-max, bbr, 几项参数就可以了,其它不要动,Linux默认的参数肯定是考虑到使用的最优化。
有没有发现,大多参数是不建议开启的。其实写这篇文章就是叫你们“住手”的,不要再糟蹋 Linux 内核了。也是因为网上大多教程对这些参数有些错误理解。Linux 的奥妙无穷,还是得好好学习之!
最后奉上俺的 sysctl 文件,结束:
vi /etc/sysctl.conf
1 | fs.file-max = 655360 |
参考: